

 一.为什么需要编解码?对于像PCIe这种无同步时钟信号协议而言,为确保电信号的正确传输,需面临如下四个信号传输质量考验:1. 时钟恢复:PCIe没有单独的时钟线,接收端需从数据信号的跳变中提取时钟,长串相同电平会导致接收端时钟失步,进而导致数据采错位(如果音乐节奏一直不变,乐队成员可能逐渐脱节) 2. 直流平衡:避免信号长时间保持高/低电平,导致接收端的电容逐渐充电或放电,进而产生电压基准漂移。(就像用弹簧秤称重,如果一直压着不放,弹簧会疲劳,读数不准) 3. 信号耦合干扰:长串相同电平会在传输线上形成稳定的电场/磁场,容易耦合外部噪声,如电源干扰。(平静的湖面更容易被风吹出波纹,而波浪起伏的湖面能掩盖小扰动) 4. 传输线效应:高频信号在传输线中会因阻抗不连续产生反射。长时间不变的电平会加剧能量累积,信号振铃(Ringing)或过冲(Overshoot),导致波形畸变。(水管中水流突然停止会引发水锤效应,冲击管道) 解决方法:对原始数据编码,使其满足: · 足够的电平跳变(供时钟恢复)。 · 0 和 1 的数量大致平衡(直流平衡)。
8b/10b 编码(PCIe Gen1/Gen2)
· 规则:每 8 位数据 转换成 10 位编码。 |
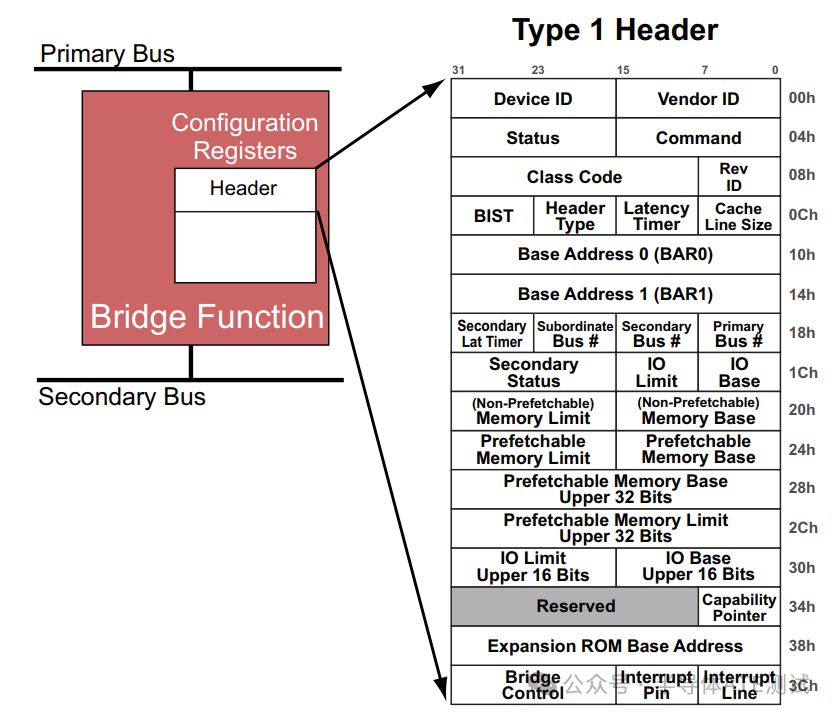
| 寄存器 | 地址偏移 | 功能 |
| Vendor ID | 0x00 | 设备厂商 ID(如 Intel: 0x8086) |
| Device ID | 0x02 | 设备型号 ID |
| Command | 0x04 | 控制设备行为(如内存/I/O 使能、总线主控) |
| Status | 0x06 | 设备状态(如链路速度、是否支持 PCIe) |
| BAR0-BAR5 | 0x10-0x24 | 基地址寄存器(映射设备内存或 I/O 空间) |
| Capabilities | 0x34 | 指向 PCIe 扩展能力链表(如 MSI/MSI-X、电源管理) |
作为PCIe 数据传输基本单元的TLP(事务层包)其Typical帧结构如下图所示:
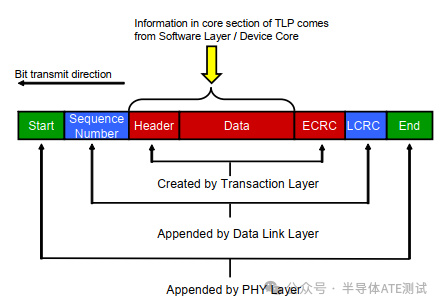
PCIe的TLP(Transaction Layer Packet)帧由三层协议协同构建,各层添加不同字段,各字段功能说明如下表:
| 字段 | 添加层 | 作用 |
| Start | PHY层 | 物理层帧起始标记(如K28.5符号,用于时钟对齐) |
| Sequence Number | 数据链路层(DLL) | 包序列号(用于ACK/NAK重传机制) |
| Header | 事务层(TL) | 包含操作类型(读/写)、地址、长度等控制信息(固定12B或16B) |
| Data | 设备核心/软件层 | 有效载荷(最大4KB,读写操作时携带数据) |
| ECRC | 事务层(可选) | 端到端CRC校验(32位),防止数据在传输过程中被篡改 |
| LCRC | 数据链路层 | 链路层CRC校验(32位),用于检测物理传输错误 |
| End | PHY层 | 物理层帧结束标记 |
其传输方向与流程可Summary 如下:
· 发送端:设备核心生成数据 → 事务层封装Header → 数据链路层加序列号和LCRC → 物理层编码并发送
· 接收端:物理层解码 → 数据链路层校验LCRC → 事务层处理Header和数据(校验ECRC)
2. 唤醒机制
PCIe 支持如下图所示,两种方式触发的低功耗状态(L0s/L1/L2/L3)唤醒:
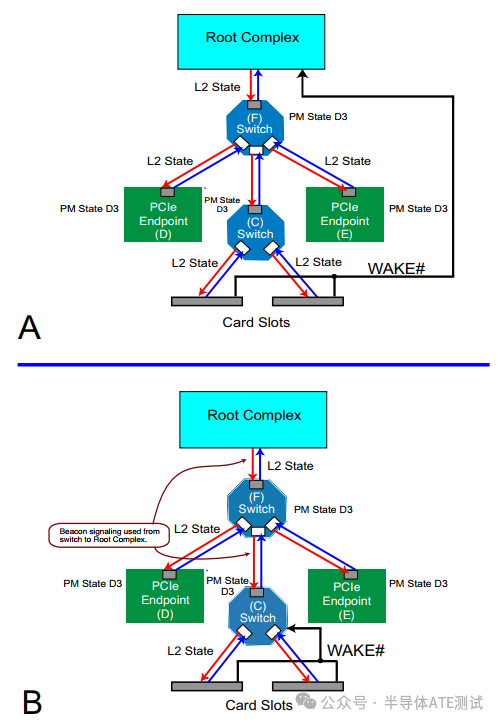
A. WAKE# 信号唤醒-硬件紧急唤醒的“救命按钮”
· 物理引脚:低电平有效,设备通过拉低 WAKE# 通知主机退出低功耗状态。
· 触发条件:Endpoint拉低WAKE#引脚(如设备检测到外部事件)
· 信号路径:Endpoint → Switch → Root Complex
· 使用场景:设备检测到外部事件(如网卡收到数据包)时触发唤醒。
· 特点:硬件级唤醒,无需协议交互;适用于D3冷启动场景;
2. 电源管理事件(PME)-协议层的“软唤醒”
· 协议层唤醒:设备通过发送 PME Message TLP 请求唤醒。· 触发条件:设备通过PCIe协议发送PME报文(需链路处于L1/L2状态)
· 信号路径:Endpoint → LTSSM状态机 → 恢复链路至L0 → 发送PME报文
· 配置支持:需在 PMCSR(Power Management Control/Status Register) 中使能 PME。
· 特点:需链路部分恢复供电(L1/L2状态); 适用于低功耗状态(非完全断电)
3. ACK/NACK
数据链路层(DLL)作为PCIe协议栈的“交警”,通过 Seq编号、LCRC校验 和 ACK/NAK机制,在不可靠的物理链路上实现了可靠传输,如下图展示了DLLP(Data Link Layer Packet)数据传输流程及TLP 数据组成:
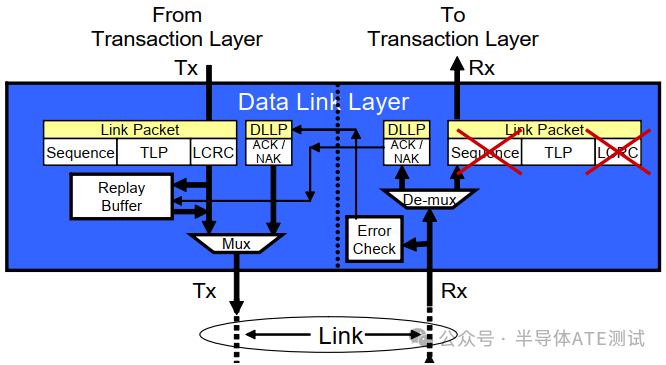
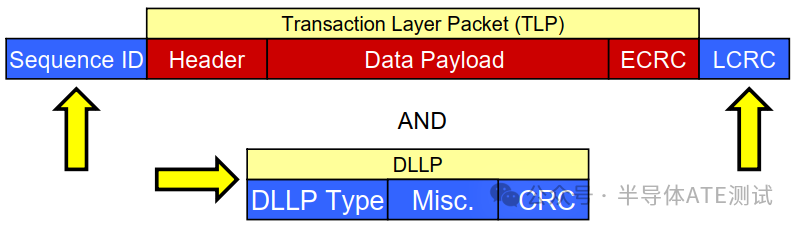
DLLP 模块详解:
| 模块 | 功能 | 关键行为 |
| Link Packet | 封装TLP为链路层数据单元 | 添加Sequence Number和LCRC |
| Sequence | 为每个TLP分配唯一序列号(如Seq=5) | 用于ACK/NAK识别和包排序 |
| LCRC | 生成32位校验码(覆盖整个TLP) | 接收方校验失败则触发NAK |
| Replay Buffer | 缓存已发送未确认的TLP(图中可能为"Display Buffer"笔误) | 收到NAK时从中重传旧包 |
| Mux/Demux | 多通道数据流调度(如x16链路分配TLP到16个Lane) | 确保多通道数据有序合并 |
| DLLP ACK/NAK | 生成/解析确认包(ACK=成功,NAK=重传) | ACK携带最新Seq号,NAK携带需重传的Seq号 |
| Error Check | 检测LCRC错误和序列号连续性 | 发现错误时触发NAK或链路重训练 |
4. 内存读写操作
· 内存读操作(Memory read)-Non-Posted Transaction 需等待CPL
Tx 端传输路径:Host 发送 Memory Read TLP → 目标设备 - Header 包含:地址、长度(如 64B)、TC(流量类别)
Rx端传输路径:设备返回 Completion TLP(CPL)→ Host - 携带请求的数据 + 状态(成功/失败)
· 内存写操作(Memory Write) -Posted Transaction 无需等待响应:
Tx 端传输路径:Host 发送 Memory Write TLP → 目标设备。 - Header + Data Payload(无需确认)
Rx端传输路径:设备直接写入内存,无显式响应(除非启用 ECRC 校验,若若启用 ECRC,接收方校验失败会触发 NACK)
| 操作类型 | TLP类型 | 是否需要回复 | 类比 |
| 内存读 | Memory Read | 需要CPLD | 网购需等快递 |
| 内存写 | Memory Write | 不需要 | 寄快递不关心对方签收 |
| 配置读写 | Configuration Rd/Wr | 需要CPLD | 查/改设备身份证信息 |
PCIe Gen3采用分层协议架构,总线周期本质上是事务层(Transaction Layer) 通过TLP(事务层包)完成的交互过程。PCIe 总线周期可分为Request->Transport-> Completion -> Ack/Nak 四个阶段:
· 请求阶段:由事务层生成TLP含地址/操作类型/数据长度,
· 传输阶段:数据链路层需要为信息添加序列号(SEQ)和CRC,物理层进行128b/130b编码;
· 响应阶段:目标设备返回完成报文(CPL或CPLD)
· 确认阶段:数据链路层通过DLLP 确认传输状态。
举个栗子:
CPU 欲从显卡读取128 B 数据:
Step1: CPU 发送TLP包(取件请求),包含:地址(数据在显卡内存中的位置),长度(128B),流量类别(TC,类似于快递加急标签)
Step2: 物理层将数据打包运输,将TLP切成更小的128b/130b编码块,通过差分线传输,每个时钟周期传8bit(Gen3速率=8GT/s)
Step3: 显卡"送货上门"(Completion TLP),显卡找到数据后,用CPLD包(Completion with Data)送回,返回快递妥投状态
Step4: CPU最终确认(ACK DLLP),CPU收到后回复ACK(类似签收短信),如果数据损坏会要求重发(NAK)
Summary:
· 总线周期本质:TLP的请求-响应交互,分层处理(事务层/数据链路层/物理层)
· 关键差异:
o 读操作需等待CPLD(Non-Posted),写操作无响应(Posted)。
· 可靠性保障:CRC校验、ACK/Nak、信用流量控制三重机制。
· 性能优化:通过Max_Payload_Size和Max_Read_Request_Size调节吞吐量。
PCIe 总线就像快递系统:TLP是包裹,DLLP是物流短信,ACK是签收回执,而x16通道就好比16个快递员同时送货,Gen3采用了更大的集装箱(128b/130b),减少了运输次数,Gen3的总线周期设计在效率与可靠性间取得了平衡,为后续Gen4/Gen5的PAM4调制奠定了基础。

